With the creation of the Coptic NLP (Natural Language Processor) pipeline by Amir Zeldes, it is now possible to run all our NLP tools simultaneously without the need to individually download and run them. The web application will tokenize bound groups into words, and will normalize the spelling of words and diacritics. It will also tag for part-of-speech, lemmatize, and tag for language of origin for borrowed (foreign) words. The interface is XML tolerant (preserves tags in the input) and the output is tagged in SGML. One of the options is to encode the lines breaks in a word or sentence which is useful for encoding manuscripts. However, keep in mind to double check results because the interface is still in the beta stage.
As an example, the screenshot below is a snippet from I See Your Eagerness from manuscript MONB.GL29.

Notice it contains an XML tag to encode a letter as “large ekthetic”. “Large ekthetic” corresponds to the alpha letter to designate it as a large character in the left margin of the manuscript’s column of text. This tag will be preserved in the output.
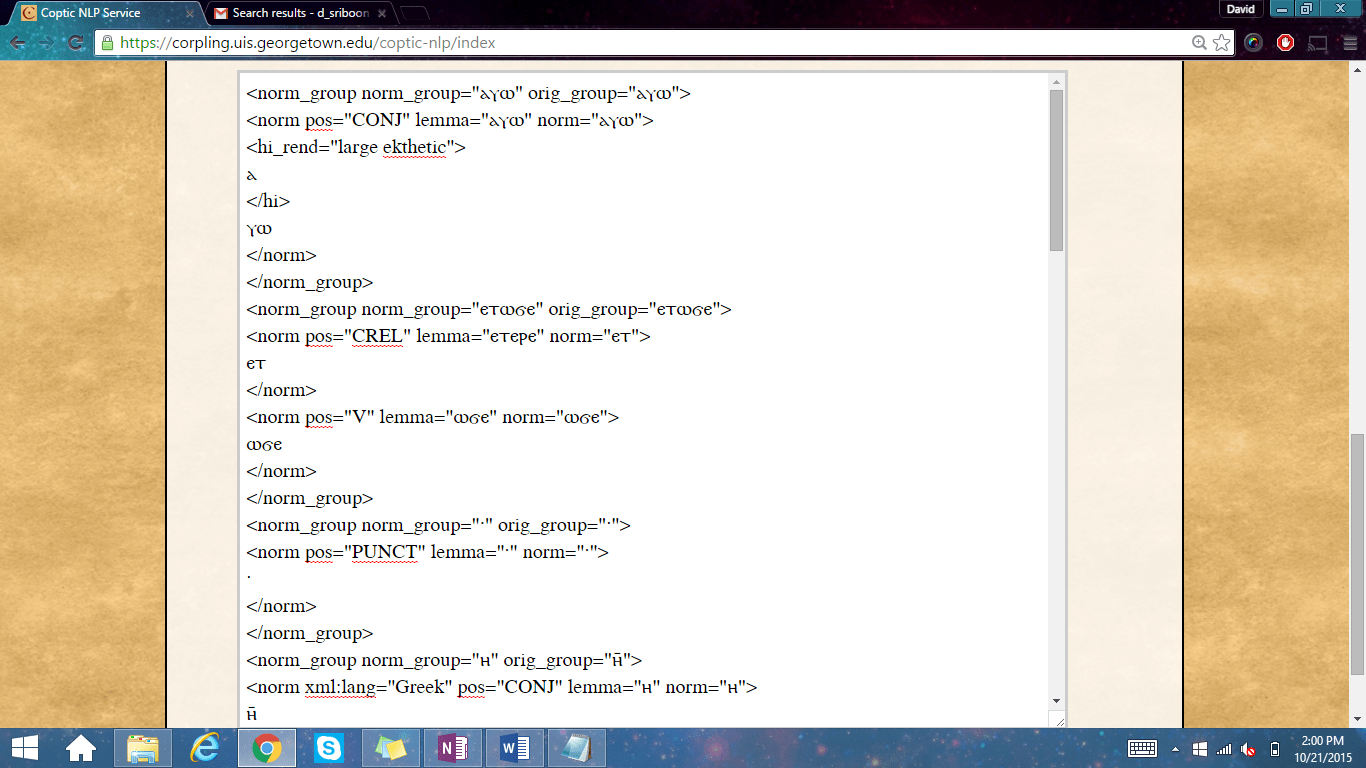
The results are shown above. Bounds group are shown and along with the part of speech tag abbreviated as “pos”. The snippet from I See Your Eagerness has also been lemmatized, shown as “lemma”. Also, near the bottom of the screenshot, the language of origin of borrowed (foreign) words in the snippet has been identified as “Greek”. These tags also correspond to the annotation layers you see in our multi-layer search and visualization tool ANNIS.
We hope the NLP service serves you well.

Leave a Reply