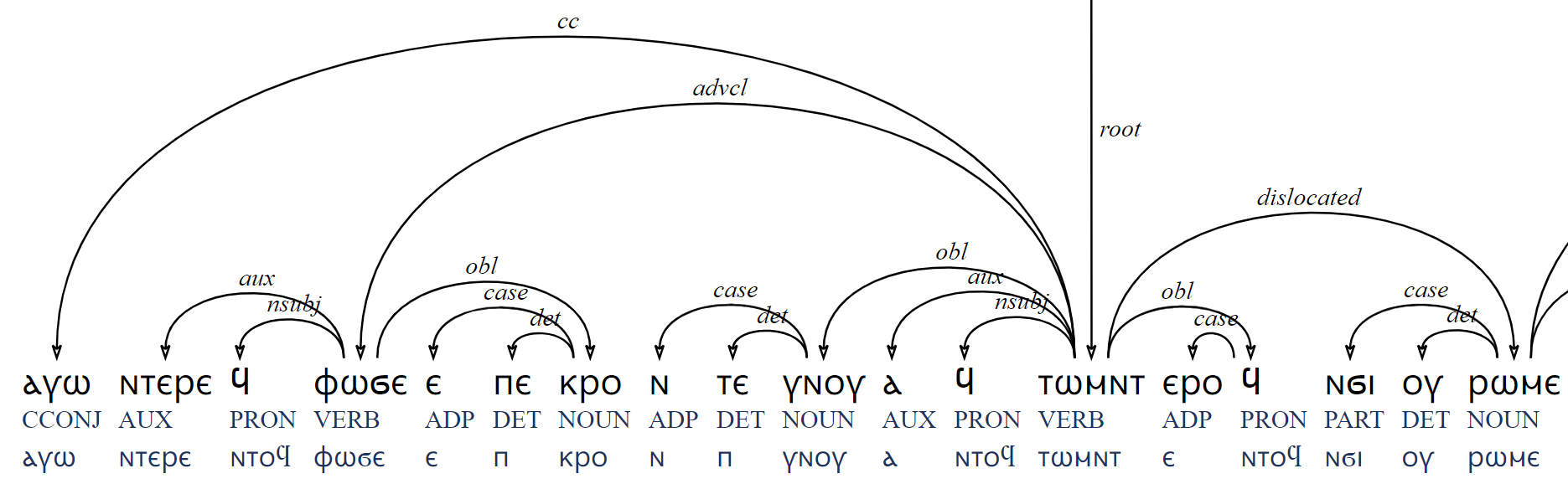
Searching for Greek loanwords in Bohairic Habakkuk
We are pleased to announce the release of version 6.0.0 of Coptic Scriptorium! Our corpus has been dramatically expanded in this release, now exceeding 2.2 million tokens of searchable, linguistically annotated Coptic texts. Among the highlights of this update is the exponential growth of our Bohairic corpus, now comprising approximately 750,000 words and featuring translated texts such as the Bohairic Bible (Old and New Testament), as well as original works such as the Life of Isaac. This milestone brings substantial enhancements to our collections, including modern editions processed with Optical Character Recognition (OCR) technology alongside both new and updated Coptic texts.
New OCR Material and Automatic Tagging
This release includes the addition of OCR-based editions. For the first time, fully automated tagging has been applied to a selection of OCR datasets:
Version 6.0.0 also includes several newly curated corpora, reflecting a diversity of dialects, genres, and textual traditions:
- More selections now with parallel Arabic translations:
- Apophthegmata Patrum (AP)
- Pseudo-Theophilus:
- Mercurius:
- Additions to Shenoute of Atripe’s Acephalous Work 22 (A22):
- Bohairic texts:
- Old Testament (automatic processing)
- New Testament (automatic processing)
- Life of Isaac (with manual corrections)
- Bohairic Bible selection manually segmented and tagged:
Collaborative Efforts and Future Directions
We are grateful to our collaborators and contributors who have made this release possible, particularly Caroline T. Schroeder and Amir Zeldes, as well as Randy Komforty, Lydia Bremer-McCollum, Lawrence Rafferty, Nina Speranskaja, and Nicholas Wagner. We also want to thank the National Endowment for the Humanities for their ongoing support. The integration of OCR materials and the expansion of our Bohairic collection reflect ongoing efforts to enhance accessibility and analytical tools for Coptic studies. These advances also pave the way for further development of NLP tools for our users.
Accessing the Data
As with all our releases, the raw machine-readable data for all corpora—including morphological and syntactic annotations, as well as named entity recognition—are available in our GitHub repository. Data can be downloaded in a variety of popular formats to suit your research needs.
For advanced linguistic queries, you can explore the data using our ANNIS server. To help you get started, check out our tutorial with query tips and a convenient cheat sheet.
We invite you to explore this latest release and we look forward to your feedback!