Coptic Scriptorium recently annotated its Treebank for entities and will soon use automated tools to annotate all corpora. Entity recognition provides a window into what a text discusses, allowing readers to discover information about people and places of interest found throughout a large number of texts that they could not possibly read exhaustively. The Coptic Scriptorium team has developed a number of tools to visualize and search for entities, which you can browse here:
https://copticscriptorium.org/entities/breakdown.html
Already, we are seeing some interesting trends. Let’s take a closer look!
TreeMapping
Entities are divided into two broad categories—named and non-named. Named entities are headed by a proper noun, e.g., “Apa Pamoun” or “Scetis.” Non-named entities, which constitute the majority of annotations, are headed by a common noun, e.g., “the monk” or “the monastery.” All entities, whether named or non-named, have one of ten entity types, such as ‘person’, ‘place’ and more (see our previous post). In the image below, we see the TreeMap of unnamed places. With the nested view of data such as this, one can easily see patterns that may be missed when viewing the information in another format.

Let’s look at the TreeMap data for non-named place entities. The desert holds an unparalleled place (no pun intended) in Coptic literature, but what exactly do Coptic texts say about it? One click of the mouse would show all eighteen mentions of entities headed by ϫⲁⲓⲉ ‘desert’ (see image below). We can see every instance of the word on the same screen and are able to compare usages. Another search would do the same for all references headed, i.e., no adjectival usages included, by the Greek word ⲉⲣⲏⲙⲟⲥ ‘desert.’ If you want to continue this line of inquiry and read every single instance of ‘desert’ in its larger context, a search for these entities in ANNIS (this function is coming soon) would display every mention in the Coptic corpora, allowing one to quickly see the texts in which these words appear and how they are used.

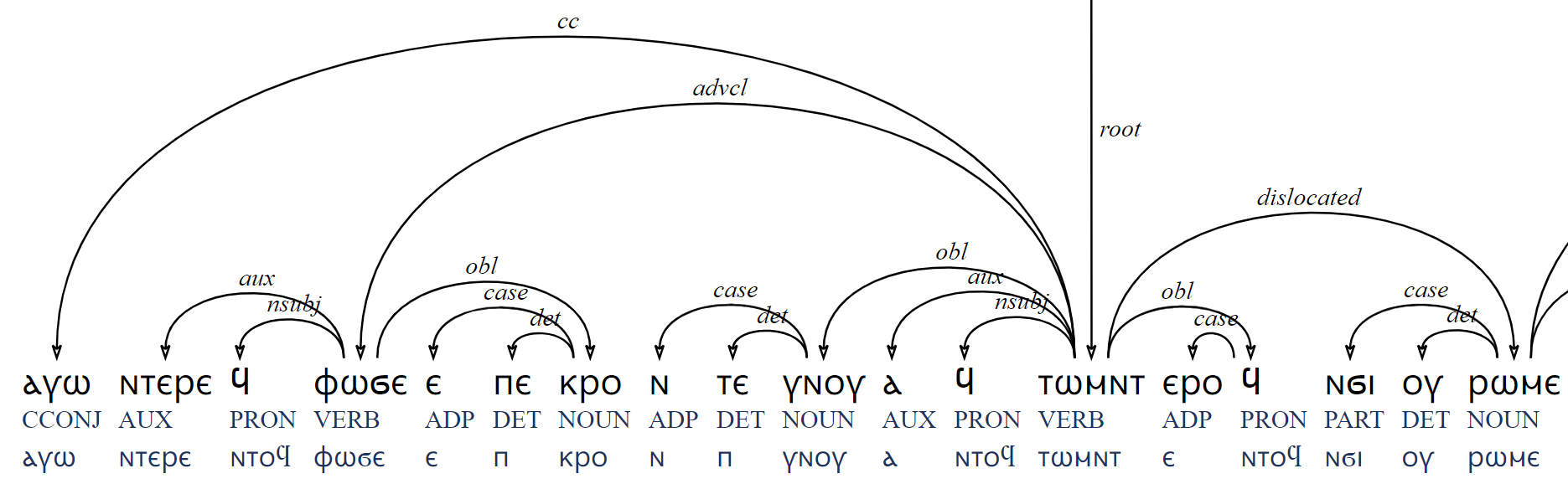
Entity Term Networking
Entity Term Networks provide a graphic visualization of an entity’s relationships with other words in its span. For an example, let’s look at ⲙⲁ ‘place.’ From the outset, we see that ⲙⲁ is used with a wide variety of determiners and is followed by an even wider variety of constructions, but we simultaneously see that attributive adjectives, such as ⲙⲁ ⲛϣ(ⲱ)ⲱⲡⲉ ‘dwelling place, monk’s cell,’ are more commonly used with ⲙⲁ than relative or genitive constructions. The entity network for ⲙⲁ gives us a clearer idea of its potential semantic relationships: almost always followed by ⲛ ‘of’, continuing to nouns indicating purpose (place of dwelling, lavatory with ⲣⲙⲏ ‘urination’), events (ϣⲉⲗⲉⲉⲧ ‘wedding’), directions (ϣⲁ ‘East’) and more. Try pulling up the network for other Coptic nouns by yourself! As with the TreeMap, the network presents a large amount of data in a small space, revealing patterns and their relative frequency more readily.

Entity Type Proportions
Entity proportions compare entity types among the corpora, visualizing them with a ratio. An average ratio is provided for all Coptic corpora and for a sample of English fiction, so viewers can see how far any given corpus departs from either baseline. The chart below sets the ratio of animals and people side by side. If you are interested in late-antique animals, you may be a little disappointed—they only appear sparsely in the corpora. Any other combination juxtaposing entity types is possible. After looking through the data, it is clear that the Coptic average has a consistently higher ratio of abstract entities than the English fiction counterpart, perhaps representative of the monastic origin of much of its corpora.

Named/Non-Named by Corpus
The last visualization compares the ratio between named and non-named entities in each corpus. Once again, there is much variation between individual works, including those of the same genre (cf. The Life of Cyrus and The Life of Onnophrius), but the ratio dissimilitude may indicate where differences in content lie, pointing the way toward further research: this surprising difference between saints’ lives may merit more attention.

What’s Next?
Entity annotation makes detailed philological, literary, and historical inquiries from a large number of documents possible by enabling analysis of texts based on the quantity, proportion and dispersion of entity types. They allow us to describe texts on a level of ‘who did what to whom’ and abstract away from individual ways of phrasing references to people and places. We’re looking forward to releasing more tools and data for working with Coptic entities!