We’re pleased to announce that we’ve released more texts in our corpora.
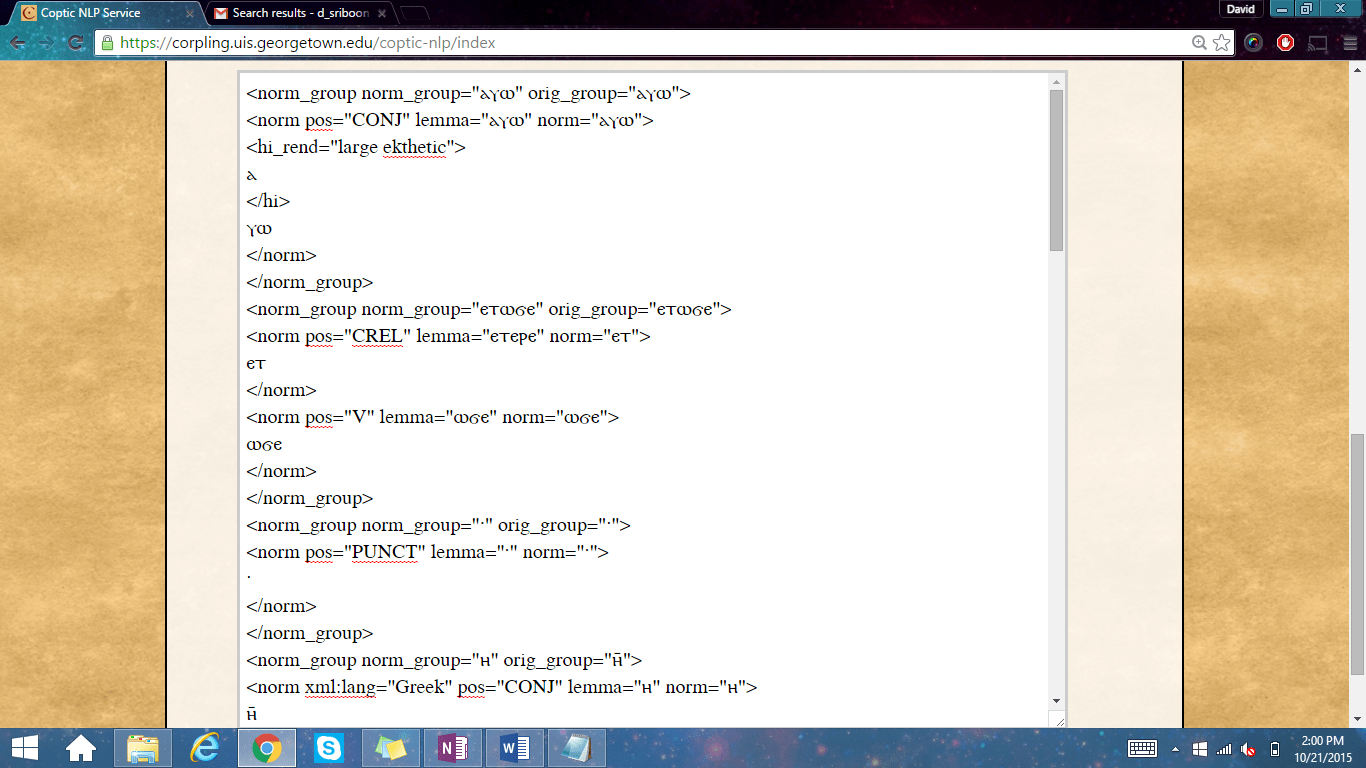
The Sayings of the Desert Fathers (Apophthegmata Patrum) corpus now contains 52 sayings/apophthegms (>7100 words). We have edited previously published sayings for consistency in annotation, and we’ve released new sayings edited by Christine Luckritz Marquis, Elizabeth Platte, and our newest contributor, Dana Robinson. Read or browse the Sayings online. Click on the “Analytic” button to see read a saying in Coptic with a parallel English translation + part of speech tags for each Coptic word.
Or click on the “Norm” button (short for “normalized”) to read the Coptic. Clicking on any Coptic word in the normalized visualization will take you to an online Coptic-English dictionary. Hovering your cursor over a passage in the normalized visualization will show the English translation in a pop up window.

AP 96 Normalized view screenshot
Shenoute’s I See Your Eagerness now has numerous new manuscript fragments published (over 16,000 words). We also have edited previously published witnesses for consistency in annotation. These documents were transcribed and collated from the manuscripts by David Brakke and annotated for digital publication by Rebecca Krawiec. Now you can read Shenoute’s I See Your Eagerness in nearly its entirety in Coptic. We provide several paths for you to explore this text:
- Read the text from start to end, beginning with the first manuscript fragment. Click “NEXT” to keep reading.

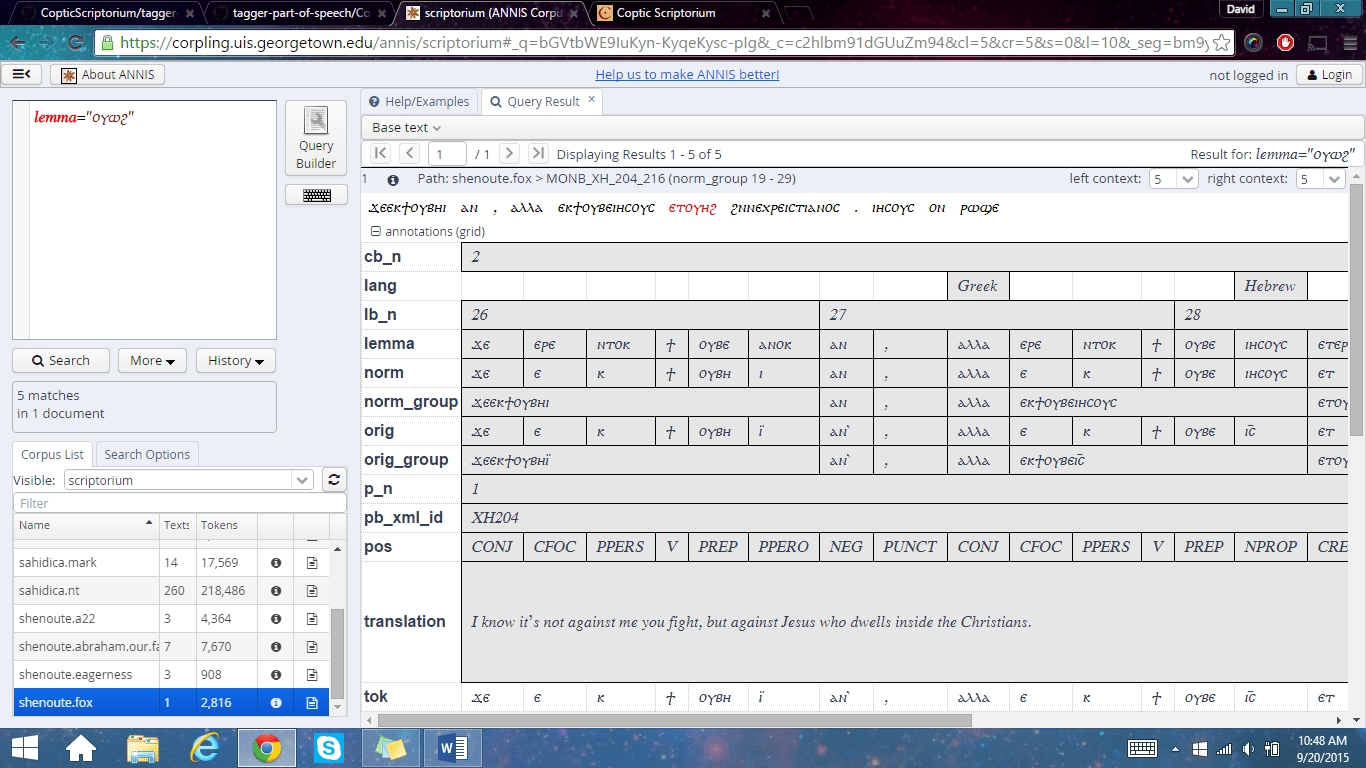
MONB.GL fragment D diplomatic visualization
(No English translation is provided, but in the “Note” metadata field below the Coptic, you can find page numbers for David Brakke’s and Andrew Crislip’s translation in their book, Discourses of Shenoute.) “Next” and “Previous” buttons will take you through the path we consider optimal for reading the text. This path wanders through various manuscript witnesses, following the path with the fewest lacunae. Want to see parallel witnesses? Check out the “Witness” metadata field below the text.

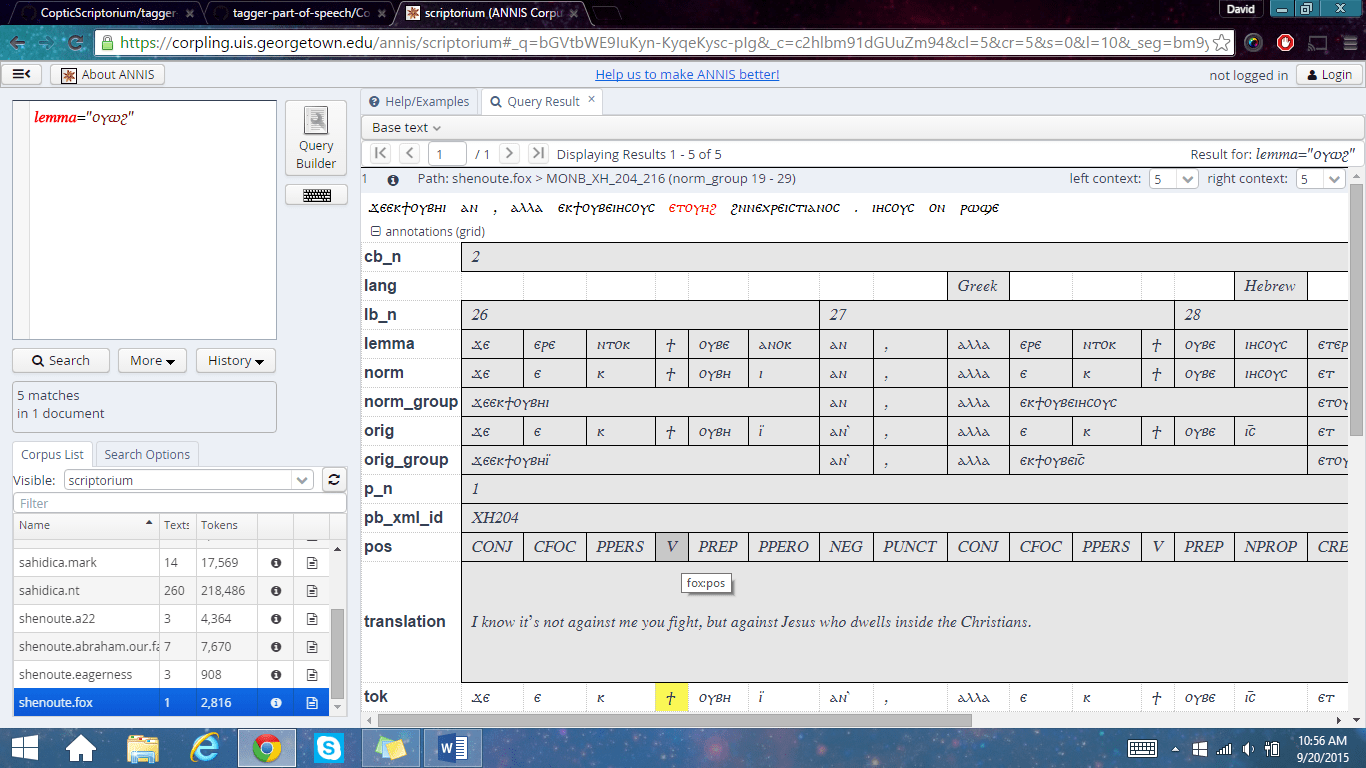
MONB.GL 29-30 metadata screenshot
- Read through all surviving pages in one codex/manuscript witness by filtering for a particular codex. Click through the documents in that codex. For example, if you want to read through all the fragments of codex MONB.GL, go to data.copticscriptorium.org, and use the menu to filter by Corpus for the shenoute.eagerness corpus, and then filter by manuscript name for the MONB.GL codex. Click through the documents in that codex.
- Perform a search/query in our ANNIS database. For example, search for all occurrences of “wicked” (ⲡⲟⲛⲏⲣⲟⲛ) in the corpus. Or, search for occurrences of “wicked” controlling for duplicate hits in parallel manuscript witnesses. See our guide to queries in ANNIS for more tips.


You also can download the entire corpus in TEI XML, PAULA XML, and relANNIS formats from our GitHub site.