We are pleased to announce release 4.4.0 of Coptic Scriptorium! Our data now includes over 1,267,000 tokens of searchable, linguistically analyzed Coptic data from dozens of ancient Coptic works (an increase of almost 100,000 tokens from the previous release). We are very grateful to all of our collaborators and contributors, without whom this project could not function.
This release corrects a large number of consistency errors identified in our existing data, and also adds some new documents:
- Sections of three works by Shenoute of Artipe:
- New documents added to existing works:
- The remaining books 2-4, as well as the postscript of Pistis Sophia, which are now added to the previously released book 1 in our online interfaces
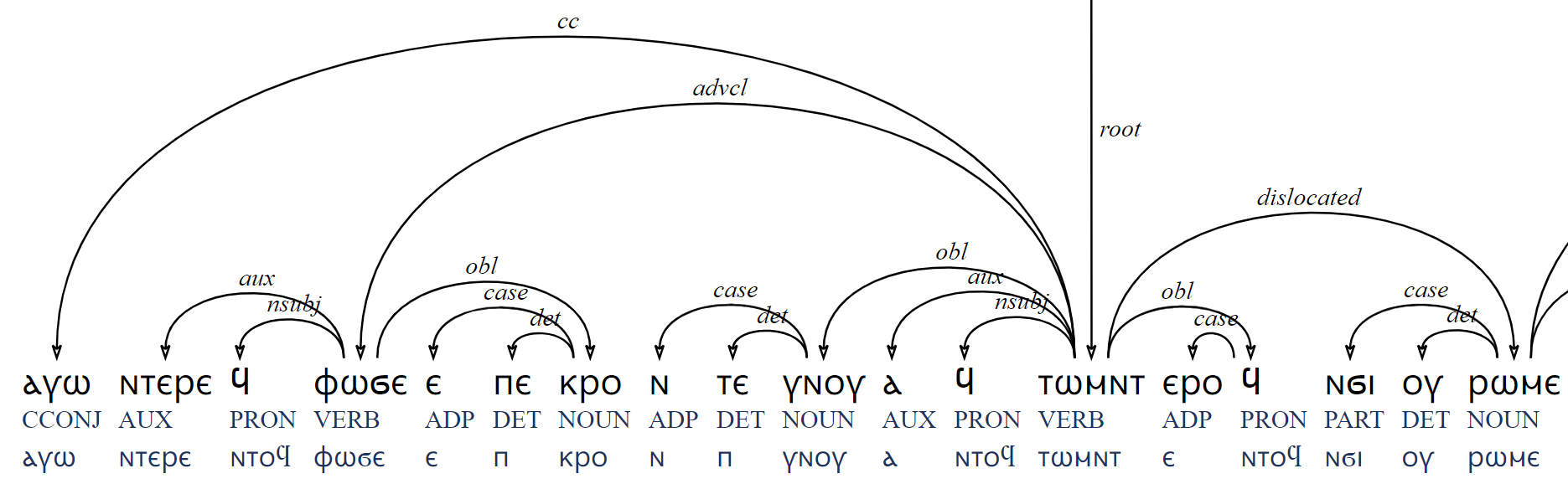
- Newly treebanked data with syntactic gold standard annotations for the Life of John the Kalybites, part 1
We would like to thank the Marcion Project for making the underlying digitized text of Pistis Sophia available, and all of the annotators for their hard work. Tamara Siuda, Rebecca Krawiec, Philippe Zaher, and Lance Martin contributed, in addition to Amir and Carrie. As our current DHAG grant ends, we would like to give special thanks to Lance, who has been working as our DH specialist on the project since 2019, for doing an amazing job of keeping track of all the data and the various tasks he’s been in charge of over the past three years!
As with all releases, raw machine readable data for all corpora can be found, including morphological and syntactic analysis, as well as named entity recognition and entity linking, on our GitHub repository, in a variety of popular formats:
https://github.com/copticscriptorium/corpora
You can also search for complex linguistic annotations in the data using our ANNIS server – please see our new tutorial here to get started with some query tips and a helpful cheat sheet:
https://copticscriptorium.org/ANNIS_tutorial
We hope this release will be useful and look forward to the next one as always!