(This post is part of a series on our 2019 summer’s work improving processing for non-standardized Coptic resources)
In this post, we present some of our work on integrating more ambitious automatic normalization tools that allow us to deal with heterogeneous spelling in Coptic, and give some first numbers on improvements in accuracy through this summer’s work.
Three-step normalization
In 2018, our normalization strategy was a basic statistical one: to look up previously normalized forms in our data and choose the most frequent normalization. Because there are some frequent spelling variations, we also had a rule based system postprocess the statistical normalizer’s output, to expand, for example, common spellings of nomina sacra (e.g. ⲭⲥ for ⲭⲣⲓⲥⲧⲟⲥ ‘Christ’), even when they appeared as part of larger bound groups (ⲙⲡⲉⲭⲣⲓⲥⲧⲟⲥ ‘of the Christ’, sometimes spelled ⲙⲡⲉⲭⲥ).
One of the problems with this strategy is that for many individual words, we might know common normalizations, such as spelling ⲏⲉⲓ for ⲏⲓ ‘house’, but recognizing that normalization should be carried out depends on correct segmentation – if the system sees ⲙⲡⲏⲉⲓ ‘of the house’ it may not be certain that normalization should occur. Paradoxically, correct normalization vastly improves segmentation accuracy, which is needed for normalization… resulting in a vicious circle.
To address the challenges of normalizing Coptic orthography, this summer we developed a three level process:
- We consider hypothetical normalizations which could be applied to bound groups if we spelled certain words together, then choose what to spell together (see Part II of this post series)
- We consider normalizations for the bound groups we ended up choosing, based on past experience (lookup), rules (finite-state morphology) and machine learning (feature based prediction)
- After segmenting bound groups into morphological categories, we consider whether the segmented sequence contains smaller units that should be normalized
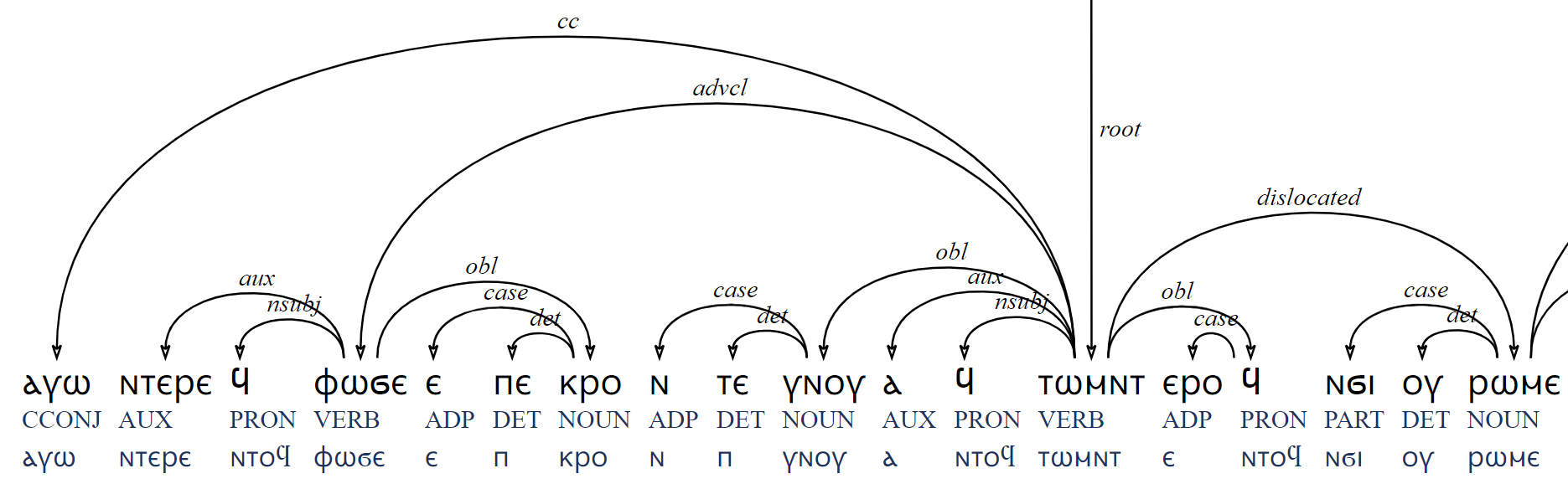
To illustrate how this works, we can consider the following example:
Coptic edition: ⲙ̅ⲡ ⲉⲓⲙ̅ⲡϣⲁ
Romanized: mp ei|mpša
Gloss: didn’t I-worthy
Translation: “I was not worthy”
These words should be spelled together by our conventions, based on Layton’s (2011) grammar, but Budge’s (1914) edition has placed a space here and the first person marker is irregularly spelled epsilon-iota, ⲉⲓ ‘I’, instead of just iota, ⲓ. When resolving whitespace ambiguity, we ask how likely it is that mp stands alone (unlikely), but also whether mp+ei… is grammatical, which in the current spelling might not be recognized. Our normalizer needs to resolve the hypothetical fused group to be spelled ⲙⲡⲓⲙⲡϣⲁ, mpimpša. Since this particular form has not appeared before in our corpora, we rely on data augmentation: our system internally generates variant spellings, for example substituting the common spelling variation of ⲓ with ⲉⲓ in words we have seen before, and generating a solution ⲙⲡⲉⲓⲙⲡϣⲁ -> ⲙⲡⲓⲙⲡϣⲁ. The augmentation system relies both on previously seen forms (a normally spelled ⲙⲡⲓⲙⲡϣⲁ, which we have however also not seen before) and combinations produced by a grammar (it considers the negative past auxiliary ⲙⲡ followed by all subject pronouns and verbs in our lexicon, which does yield the necessary ⲙⲡⲓⲙⲡϣⲁ).
The segmenter is then able to successfully segment this into mp|i|mpša, and we therefore decide:
- This should be fused
- This can be segmented into three segments
- The middle segment is the first person pronoun (with non-standard spelling)
- It should be normalized (and subsequently tagged and lemmatized)
If normalization had failed for the whole word group, there is still a chance that the machine learning segmenter would have recognized mpša ‘worthy’ and split it apart, which means that segmentation is slightly less impacted by normalization errors than it would have been in our tools a year ago.
How big of a deal is this?
It’s hard to give an idea of what each improvement like this does for the quality of our data, but we’ll try to give some numbers and contextualize them here. The table below shows an evaluation on the same training and test data: in-domain data comes from UD Coptic Test 2.4, and out-of-domain data represents two texts from editions by W. Budge: the Life of Cyrus and the Repose of John the Evangelist, previously digitized by the Marcion project. The distinction between in-domain and out-of-domain is important here, as in-domain evaluation gives the tools test data that comes from the same distribution of text types the tools are trained on, and is consequently much less surprising. Out-of-domain data comes from text types the system has not seen before, edited with very different editorial practices.
|
2018 |
2019 |
| task |
in domain |
out of domain |
in domain |
out of domain |
| spaces |
NA* |
96.57 |
NA* |
98.08 |
| orthography |
98.81 |
95.79 |
99.76 |
97.83 |
| segmentation |
97.78 (96.86**) |
93.67 (92.28**) |
99.54 (99.36**) |
96.71 (96.25**) |
| tagging |
96.23 |
96.34 |
98.35 |
98.11 |
* In domain data has canonical whitespace and cannot be used to test white space normalization
** Numbers in brackets represent automatically normalized input (more realistic, but harder to judge performance of segmentation as an isolated task)
The numbers show that several tools have improved dramatically across the board, even for in-domain data – most noticeably the part of speech tagger and normalizer modules. The improvement in segmentation accuracy is much more marked on out-of-domain data, and especially if we do not give the segmenter normalized text as input (numbers in brackets). In this case, automatic normalization is used, and the improvements in normalization cascade into better segmentation as well.
Qualitatively these differences are transformative for Coptic Scriptorium: the ability to handle out-of-domain data with good accuracy is essential for making large amounts of digitized text available that come from earlier digitization efforts and partner projects. Although 2018 accuracies on the left may look alright, the reduction in error rates is more than half in some cases (7.72% down to 3.75% in realistic segmentation accuracy out-of-domain). Additionally, the reduced errors are qualitatively different: the bulk of accuracy up to 90% represents easy cases, such as tagging and segmenting function words (e.g. prepositions) correctly. The last few percent represent the hard cases, such as unknown proper names, unusual verb forms and grammatical constructions, loan words, and other high-interest items.
You can get the latest release of the Coptic-NLP tools (V3.0.0) here. We plan to release new data processed with these tools soon – stay tuned!